Human-in-the-Loop is sold as a quality guarantee for the decisions an AI makes. In practice it is a business-comfort zone – a place where a living person carries the responsibility for decisions they do not actually control.
Verification debt: almost everyone doubts, fewer than half verify
A fresh Sonar survey (2026, more than 1,100 developers) found that 96% doubt the correctness of AI-generated code, but fewer than half actually verify it before committing. Werner Vogels, CTO of AWS, named the phenomenon verification debt: AI speeds up writing code while eroding the engineer’s understanding of what they just committed.
This is the moment every self-respecting person in the AI world reaches for the phrase “human in the loop.” It sounds great – great for a clever line on a date, over a beer at the bar, or in a meeting. But once you look at where the phrase actually comes from, you find an interesting backstory.
Where the “crumple zone” came from
Every modern car has a so-called crumple zone. It is engineered in deliberately: the part of the body that takes the main impact in a crash, absorbs the energy, and in doing so protects the driver and the passenger.
In 2019, anthropologist Madeleine Clare Elish of Data & Society took that idea and coined the term moral crumple zone: a human inside a complex automated system can become exactly that kind of absorbing component – except that, unlike in a car, this crumple zone does not protect the human, it protects the system, and it does so at the human’s expense.
That is the short history of “human in the loop.”
The Sonar numbers and an awkward question
Sonar surveyed 1,100+ developers in January 2026. The result: 96% are not confident in the functional correctness of AI-written code. And how many of those developers actually verify that code – you probably expect 96%? Unfortunately, fewer than half.
What does this have to do with vigilance theory?
What vigilance theory actually says
Vigilance research is a relatively young field – roughly seventy years old. In the mid-20th century, researchers sat people in front of monotonous data streams and asked them to watch for a rare signal. Again and again they got the same result: the longer you wait for a rare event inside a monotonous stream, the worse you are at noticing it. There is still no satisfying answer for why the brain works this way, but the effect is reliably reproducible.
What did humanity do with that knowledge? It plugged AI directly into exactly that paradigm. Surprising? Not at all. The business wants fast decisions – faster, faster, and faster again.
A human was put “in the loop” not to make the decisions. They were put there so that someone is available to take the hit when the decision turns out to be bad. So you can fire the person who failed to save the system from a disastrous 500-file pull request that the AI produced in an hour, handed to a developer for review thirty minutes before the end of the workday.
Convenient? Of course.
Control, or alibi?
The real question is different: is “human in the loop” about control, or about an alibi for the business? About finding the right scapegoat to fire and then continuing down the same well-worn path to a complete collapse of the process?
I am convinced that a human neither should – nor can – control the decisions of a machine in ordinary routine processes. It makes no sense: the human will, on average, agree with the system. That is how our brain is wired.
What about pilots and nuclear-plant operators?
But surely there are domains where we have used “human in the loop” without LLMs successfully for decades – pilots, nuclear-plant operators, and so on. Yes. And we forget that those are not millions of people, and they are not people pulled off the street. They are experts – experts who are trained to notice even small statistical deviations in the system’s behavior, and who almost never work alone. They cross-verify each other’s decisions. These are expert decisions.
That is why Expert-in-the-Loop is the honest version of the same idea.
What expert review looks like in code
Rather than asking a human to scan every diff for the rare meaningful change, an Expert-in-the-Loop setup describes – once – what “safe enough” means, and then enforces it on every PR. Here is what that looks like in the Talon language:
// ── Definitions ────────────────────────────────────────
define "small_change" {
"pr.lines_changed" < 50
"pr.files_changed" < 5
}
define "critical_path" {
"pr.touches_auth" == true
or "pr.touches_payments" == true
or "pr.touches_database_schema" == true
or "pr.touches_infrastructure" == true
}
define "touches_data_layer" {
"pr.touches_elasticsearch_queries" == true
or "pr.touches_sql_queries" == true
or "pr.touches_migrations" == true
}
define "ui_change" {
"pr.touches_css" == true
or "pr.touches_components" == true
or "pr.touches_templates" == true
}
// ── Auto-deploy to a test environment ──────────────────
rule "Deploy every non-critical PR to a preview environment" {
when "pr.tests_passing" == true
and not is "critical_path"
do deploy_preview "pr"
do comment "pr" "Preview deployed at {preview.url}"
}
// ── A/B check the parts the PR claims to change ────────
rule "Run A/B on features mentioned in the PR description" {
when "preview.status" == "deployed"
and "pr.description.features" not empty
do ab_test "preview.url" "production.url" "pr.description.features"
do wait_for "ab_test.sample_size" >= 5000
}
rule "Block when A/B shows regression on a tracked feature" {
when "ab_test.delta.conversion" < -0.02
or "ab_test.delta.error_rate" > 0.05
do block "pr.merge"
do comment "pr" "A/B regression detected: {ab_test.report_url}"
}
// ── Validate ES and DB queries the PR touches ──────────
rule "Explain plan for every changed SQL query" {
when "pr.touches_sql_queries" == true
do run "explain_analyze" "pr.changed_queries"
do require "explain.rows_scanned" < 1000000
do require "explain.uses_index" == true
}
rule "Block slow Elasticsearch queries introduced by the PR" {
when "pr.touches_elasticsearch_queries" == true
do run "es_benchmark" "pr.changed_queries"
do require "es_benchmark.p95_ms" < 250
do block_when "es_benchmark.p95_ms" >= 250
do comment "pr" "ES p95 {es_benchmark.p95_ms}ms exceeds 250ms budget"
}
rule "Migrations must be reversible and dry-runnable" {
when "pr.touches_migrations" == true
do run "migration.dry_run"
do require "migration.has_down" == true
do require "migration.dry_run.status" == "ok"
}
// ── Check metrics in the preview environment ───────────
rule "Compare preview metrics with production baseline" {
when "preview.status" == "deployed"
do collect_metrics "preview" "5m"
do require "preview.metrics.p95_latency_ms" <= "baseline.p95_latency_ms" * 1.10
do require "preview.metrics.error_rate" <= "baseline.error_rate" * 1.50
do require "preview.metrics.memory_rss_mb" <= "baseline.memory_rss_mb" * 1.20
}
rule "Block on metric regression" {
when "preview.metrics.error_rate" > "baseline.error_rate" * 2.0
do block "pr.merge"
do comment "pr" "Error rate doubled vs baseline -- see {preview.metrics.dashboard_url}"
}
// ── Auto-approve when everything looks clean ───────────
rule "Auto-approve safe PRs" {
when is "small_change"
and "pr.tests_passing" == true
and not is "critical_path"
and not is "touches_data_layer"
and "preview.metrics.regressions" == 0
and "ab_test.delta.error_rate" <= 0
do approve "pr"
do emit "notify_author"
}
// ── Reserve humans for the rare meaningful case ────────
rule "Escalate to a senior engineer on critical paths" {
when is "critical_path"
do require "review.senior_engineer"
do assign "pr" "team.senior_oncall"
do comment "pr" "Critical path -- human approval required"
}
rule "Escalate when data-layer changes look risky" {
when is "touches_data_layer"
and ("explain.rows_scanned" >= 1000000
or "es_benchmark.p95_ms" >= 250)
do require "review.data_team"
do comment "pr" "Data-layer regression flagged -- data team review required"
}
What changed? The human is no longer in the path of small diffs where vigilance does not work anyway. They step in only when something measurable has gone wrong – a slow SQL plan, a hot Elasticsearch query, an A/B regression, an error-rate spike against the baseline. The rules themselves are written by humans, reviewed by humans, and stored next to the code they govern. That is human judgment in the system, applied once and consistently, instead of human attention sprayed thinly across every PR.
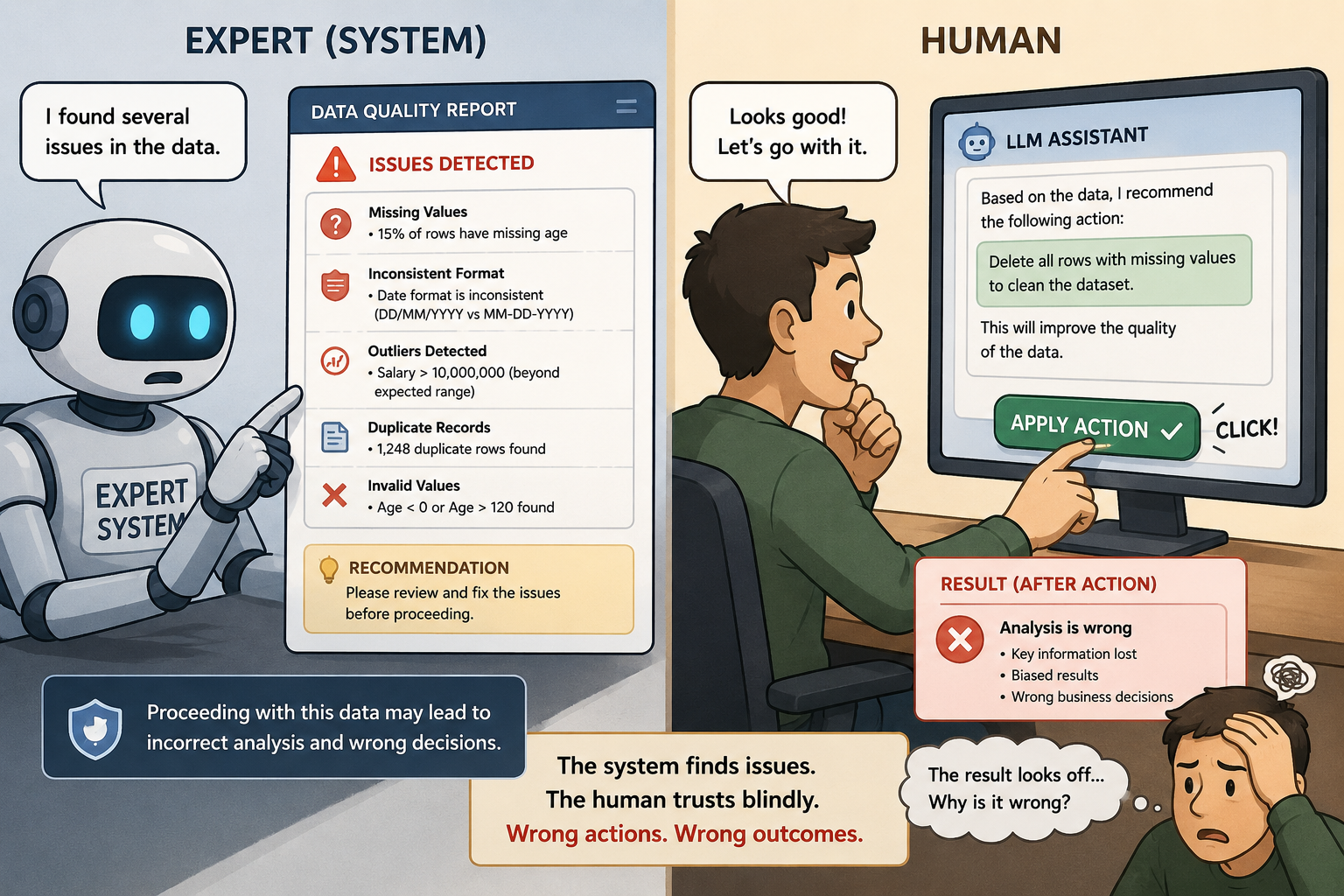
Can the expert also be a machine?
Here is the underlying question: can the expert be not only a person, but a machine? Society answered that one a long time ago, with the appearance of expert systems.
Acknowledgements
Thanks to Vitaliy Shelest for the great insights and ideas that shaped this article.
Further reading
- First_Light, “Human-in-the-Loop as Accountability Theater” – the Habr article this post is in dialogue with (in Russian).
- Expert in the Loop (EITL) – why “the human approves everything” is not control, but a replacement for it.
- LLM, Neural Network, or Expert System? – on the boundary between probabilistic and deterministic decisions.